Feature Selection for High-Dimensional Data Based on a Multi-objective Particle Swarm Optimization with Self-adjusting Strategy Pool
- Author: Yingyu Peng, Ruiqi Wang, Dandan Yu & Yu Zhou
- Accepted: 2022
- Published in: Neural Computing for Advanced Applications( NCAA 2022 )
- Paper Link
- code:https://github.com/EMRGSZU/papers-code
Abstract
The development of data collection increases the dimensionality of the data in many fields, which might even cause the curse of dimensionality, arising a challenge to many existing feature selection. This paper proposes a method based on a feature prioritization approach and a multi-objective particle swarm optimization with self-adjusting strategy pool (MOPSO-SaSP). The proposed algorithm adopts a backward filter approach based on Approximate Markov blankets as a preprocessing step which prioritizes features into predominant features and subordinate features to reduce the search space and lessen the randomness of the initialization step. Afterwards, an adaptive mechanism is applied that enables each particle to adaptively choose a strategy from the strategy pool according to the latest information collected. The strategy pool is constructed through a series of experiments on training data. Different strategies specialized in different searching methods. Experimental results on eight benchmark micro-array gene datasets reveal that the feature prioritization approach can deal features in an efficient way and the adaptive mechanism is a powerful searching method to achieve a competitive classification accuracy and reduce the number of features.
The Proposed Method
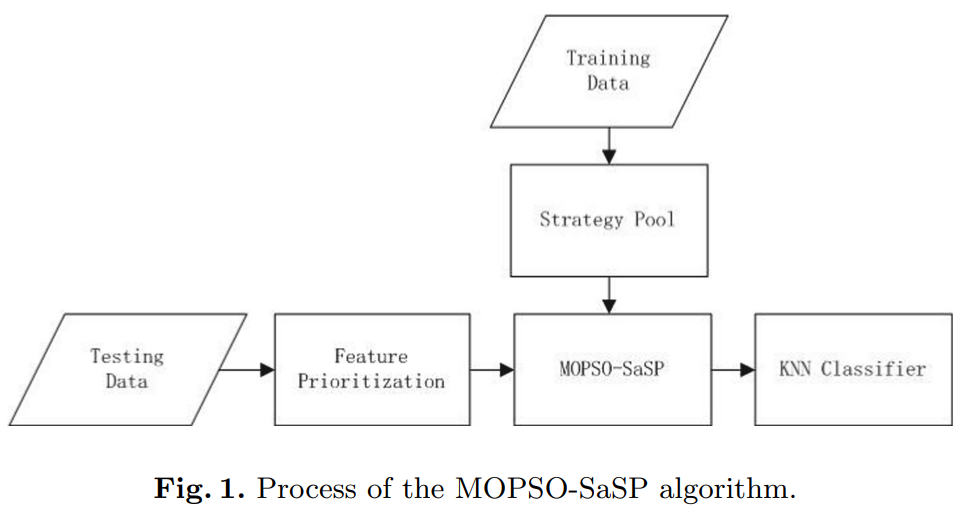
The overall flow of the proposed method is shown in Fig. 1. At first, a feature prioritization approach based on Approximate Markov Blanket (AMB) is applied to divide relevant features into predominant features and subordinate features. Then, with the self-adjusting strategy pool, MOPSO-SaSP is applied to gain the Pareto optimal solutions. At last, the candidate solution with the highest classification accuracy is taken as the selected feature subset.