Feature library-assisted surrogate model for evolutionary wrapper-based feature selection and classification
- Author: Hainan Guo , Junnan Ma , Ruiqi Wang , Yu Zhou
- Accepted: 19 March 2023
- Published in: Applied Soft Computing( ASOC )
- Paper Link
- code:https://github.com/EMRGSZU/papers-code/tree/main/FL-SM
Abstract
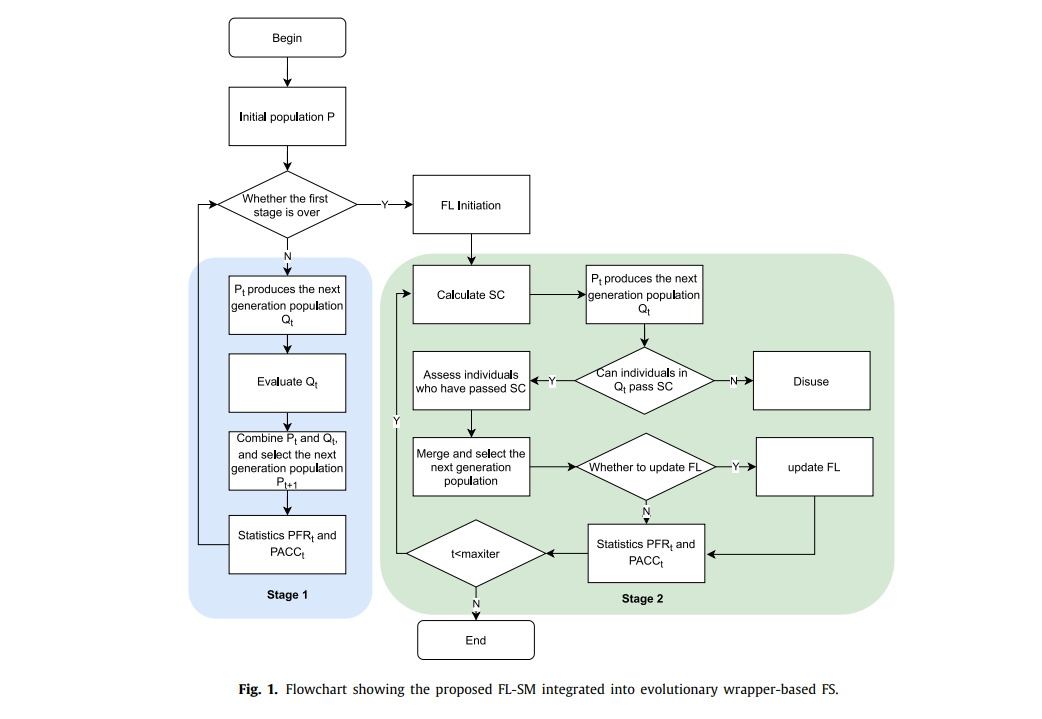
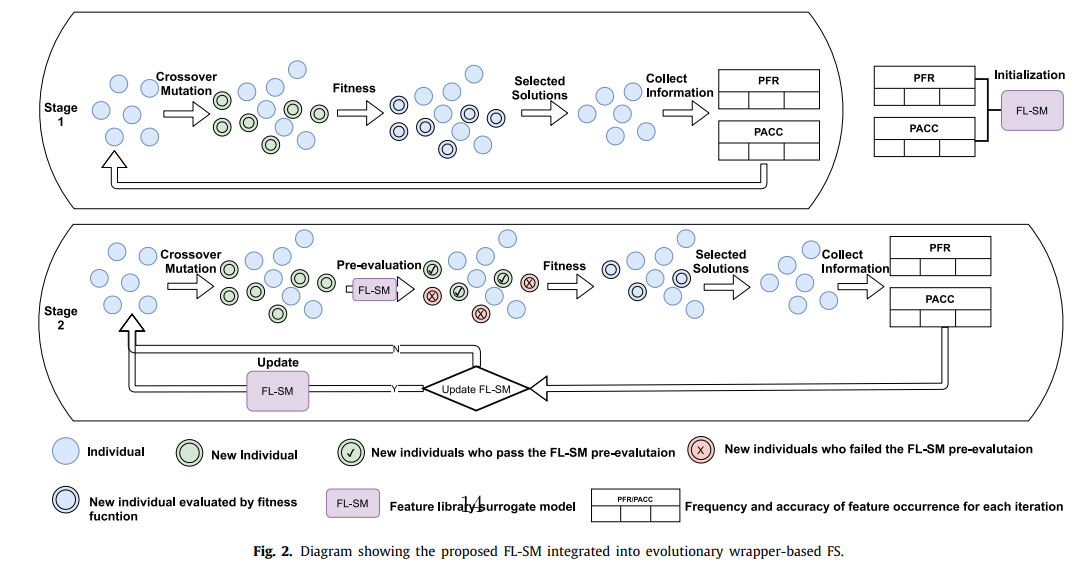
In recent years, wrapper-based feature selection (FS) using evolutionary algorithms has been widely studied due to its ability to search for and evaluate subsets of features based on populations. However, these methods often suffer from a high computational cost and a long computation time, mainly due to the process of evaluating the feature subsets according to the classification performance. In order to tackle this problem, this paper presents a feature library-assisted surrogate model (FL-SM), which aims to reduce the computational cost but maintain a good prediction accuracy. Unlike the existing surrogate models used in FS, the proposed method focuses on the feature level instead of the sample level: an FL is built by collecting the scores of all the features during the evolutionary search. Specifically, each solution (subset candidate) is pre-evaluated based on the FL using only simple operations to decide whether or not it deserves to be evaluated by the classifier, improving the efficiency of the FS algorithm. Meanwhile, because not evaluating a certain number of solutions may lead to inaccurate solution selection during the evolutionary search, dynamic individual selection criteria are proposed. In addition, an adaptive FL update operator is proposed to handle the dynamics of the evolved population; it ensures the real-time validity of the FL. Furthermore, we incorporate the proposed FL-SM into some state-of-the-art single- and multi-objective evolutionary FS methods. The experimental results on benchmark datasets show that with good flexibility and extendibility, FL-SM can effectively reduce the computational cost of wrapper-based FS and still obtain high-quality feature subsets. Among the five algorithms tested, the average computation time reduction was 34.87%; at the same time, there was no significant difference in the classification accuracy for 80% of the tests, and our method even improved the classification accuracy for 6% of the tests.